



谷歌翻译夹带私货,涉及中国就乱翻译?其实真相是这样的(组图)
这几天,我所在的好几个语言学研究群和英语教师群都在转这样一个帖子:
大概内容是,H大姐发了一个英文twitter,原文是这样的:
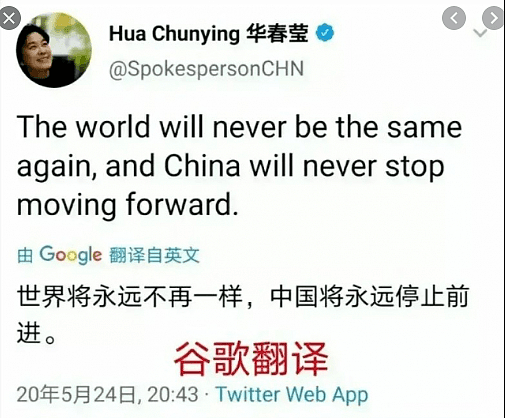
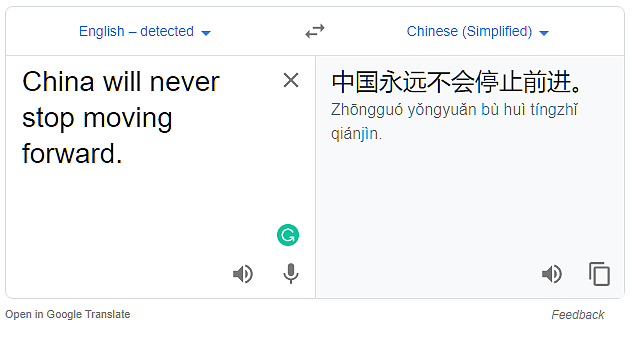
The world will never be the same again, and China will never stop moving forward.
这句话意思很简单,就是:世界将不再和以前一样,中国也绝不会停下前进的脚步。
然而,就是这么一个简单的意思,twitter内嵌的谷歌翻译还给整错了,后半句居然翻译成了完全相反的意思:中国将永远停止前进。(见下图)
这是怎么回事儿?
别盲从,请验证
看到这种事儿,估计很多人的第一反应就是:谷歌翻译夹带私货,恶意针对中国。
有这种反应很正常,毕竟爱国情怀人皆有之。但如果我们总是让本能的反应支配自己的行为的话,恐怕不但不能为国做出真正的贡献,还会沦为被收割的韭菜。
目前大多数,不,应该说是绝大多数自媒体,如果讲到这个事情,都会把结论引向某种程度的阴谋论,比如谷歌翻译有意抹黑中国。
但本公众号不属于这“绝大多数”。有别于那些收智商税的,我写文章也是为了做语言学科普,这其中也包括逻辑思维、概率思维的科普。所以,我不会止步于简单粗暴的阴谋论,而是要去探究一下,为什么谷歌翻译会犯这样低级的错误。
探究、探究、再探究
第一步:对比多个翻译引擎结果
显然,谷歌的翻译是有问题的,那么其它翻译引擎呢?
我把H大姐的英文原文放进了几个主流的机器翻译引擎里,结果分别如下:
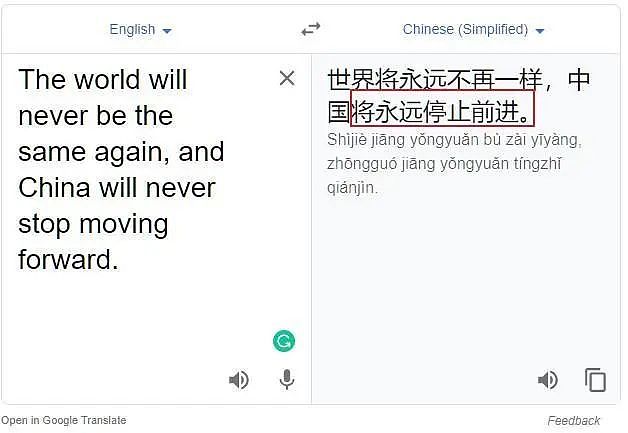
首先是谷歌翻译。结果显示,无论是twitter调用还是谷歌翻译网页版,翻译结果都是错误的。
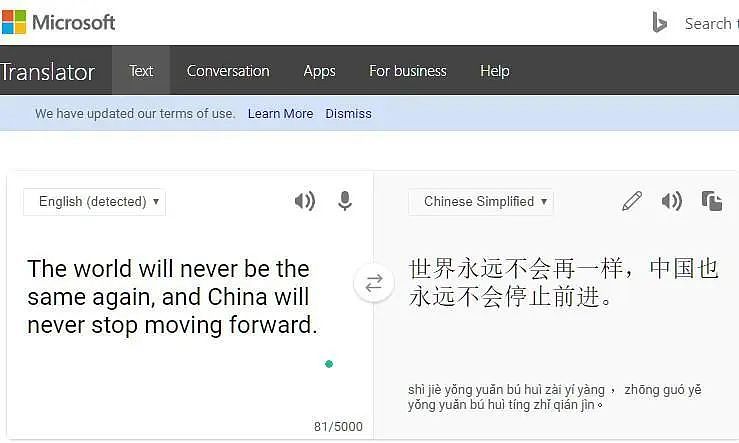
必应翻译没有问题。
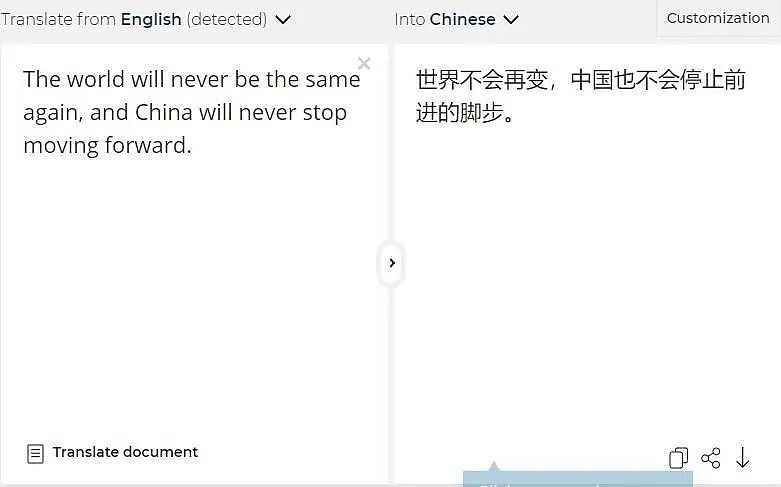
DeepL是机器翻译领域的新秀,但大有后来居上之势。不过,遗憾的是,虽然它把后半句翻译对了,但前半句却错了。
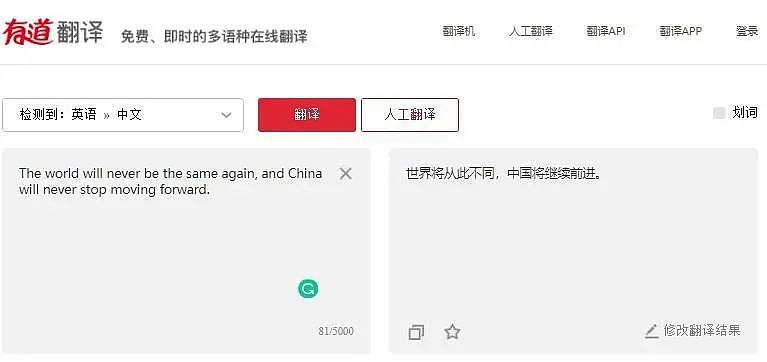
中英互译是有道翻译的特长,毕竟是中国本土的产品。有道翻译的中文译文显然较其它引擎更为简洁,更像中文。
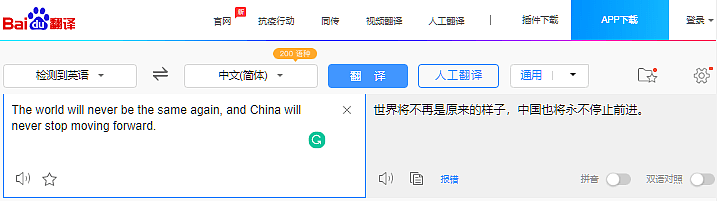
百度翻译意思上也没有问题,但文采上略输有道。
结论一:在后半句的翻译上,谷歌确实有问题。那么,问题出在哪里呢?
第二步:假设问题出在China上,检验假设
如果谷歌翻译针对中国有特殊的设置,那么如果我们把中国替换掉,翻译结果就会不同。下面我们把原文里的China替换为Russia,Japan和the US,看下结果如何。
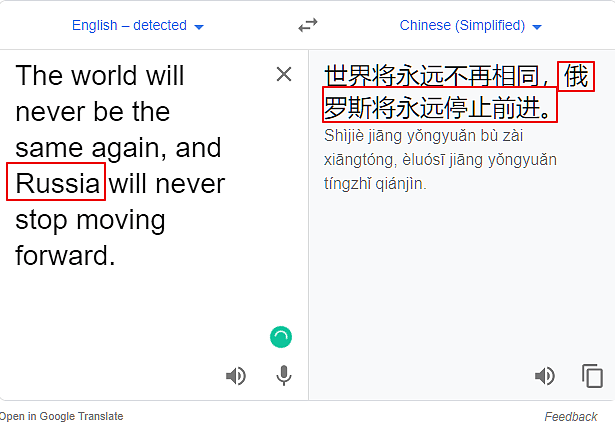
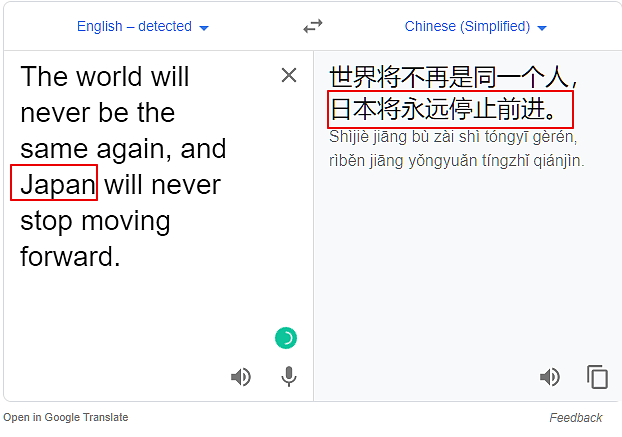
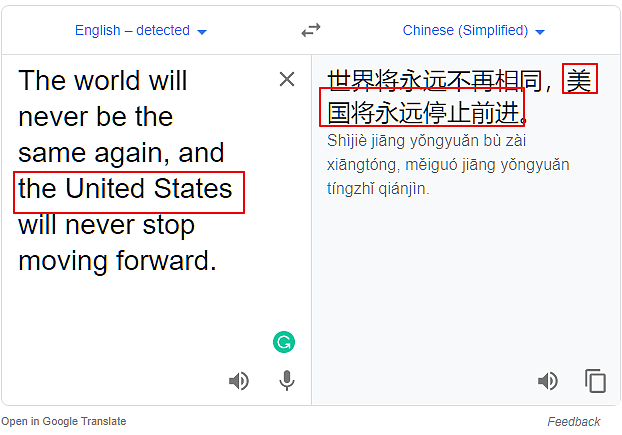
结果显示,无论是美国电影里长期的美国假想敌,还是美国的盟友,还是美国自己,在谷歌翻译里,都一视同仁,都别想前进。看吧,谷歌狠起来,自己的祖国都不放过。
结论二:谷歌翻译并没有针对China特别设置,只要是在这个结构中,换哪个国家,翻译结果都是一样的。
第三步:假设问题出在moving forward上,检验假设
现在我们已经知道国名不是造成误译的原因,那么问题是不是出在moving forward上呢?顺便说一下,之所以我会先假设问题出在China和moving forward上,是因为这两个是句子里最重要的成分,所以先检验它们。
我们把moving forward换成fighting,结果如下:
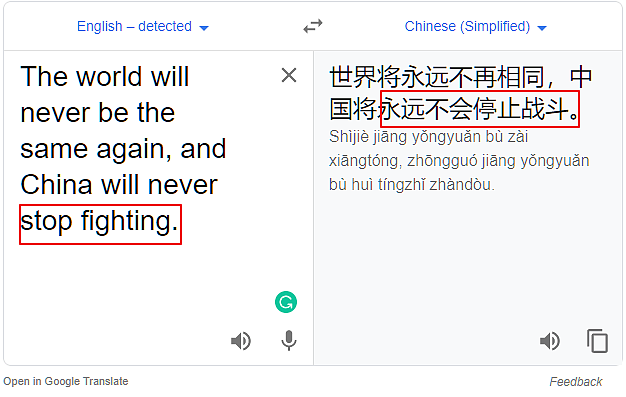
换成developing:
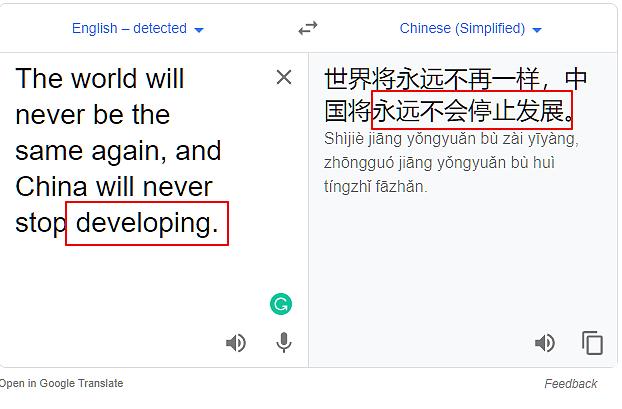
结论三:在原文的结构里,用moving forward,谷歌就会误译,而用其它动词,则可能不会。当然,我不可能检测完所有的动词,所以说可能不会。
第四步:假设问题出在will和moving forward的组合上
从上一步里,我们可以看出moving forward是造成误译的原因之一。但很可能它不是唯一的原因,因为它本身还用在更大的结构里,所以我们来看一下情态动词的变化会不会造成翻译结果的改变。
把will换成would:
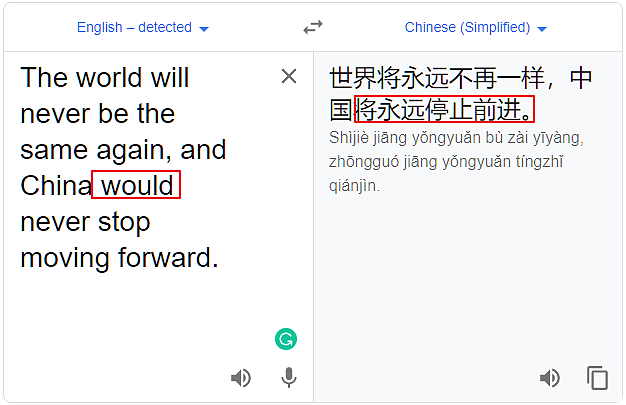
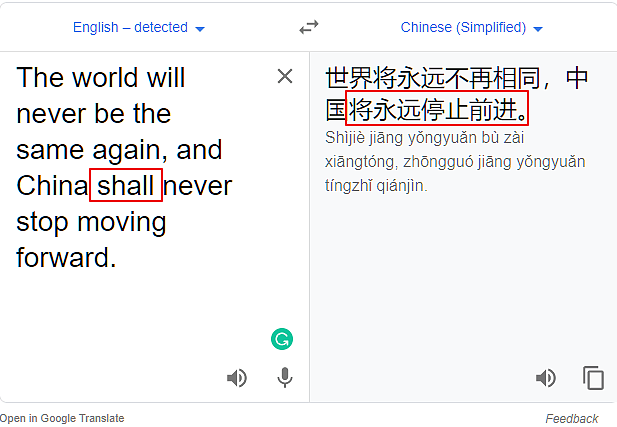
把will换成shall(这个情态动词现在很少用了):
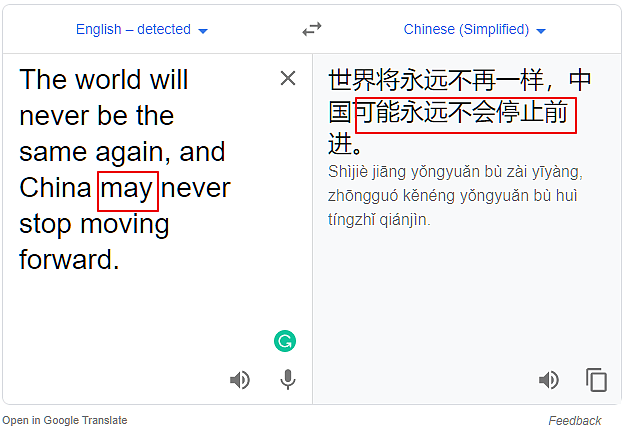
把will换成may:
把will换成might:
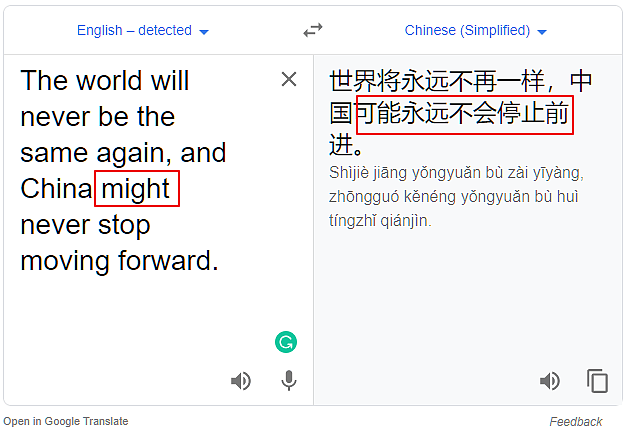
有意思了,用would和shall,都会出现误译,但用may和might却不会。我又试了could和can,也不会误译。
结论四:在谷歌翻译里,当will、would、shall never stop和moving forward连用时,会出现误译。
第五步:假设问题出在更大的语境,检验假设
其实,从上面的试验中,我们并不能得出will never stop moving forward一定会被误译的结论,因为我们没有考察另一个可能性,那就是,前半句的存在造成了后半句的误译。所以,我们把前半句去掉看一看:
果然,去掉前半句后,翻译正确了。很多自媒体就是把去掉前半句的Google翻译作为证据,证明twitter内嵌的Google翻译是夹带了私货。这就是搞笑了。句子都被你改了,还拿来对比,这不是耍流氓吗?
结论五:在存在其它分句的情况下,当will never stop和moving foward在一起时,谷歌翻译会出现误译。
可能的原因
我上面写这么多,主要是想告诉大家,不要着急下结论,要多思考、多探究。养成这个好习惯,你才能避免沦为韭菜的悲剧。一旦你没有这种习惯,你唯一的幸福来源就是无知了。而且为了这种低级幸福感,你会主动保持无知。这是恶性循环,一旦陷入,几乎不太可能走出来。
就本文讨论的问题而言,还有一种情况可以让你立马看出很多自媒体结论的荒谬,那就是你具备相应的背景知识。实际上,对于我来说,根本无需上面的研究过程,我就知道“谷歌翻译夹带私货”这种结论的可笑。
现在的机器翻译,背后都是深度网络模型。深度网络模型是端对端的模型,中间的隐层是黑箱。如果要针对某一个词做特别的处理,至少要做两件事情:
第一,要在输入端把是否包含这个词作为一个显性的特征。
第二,训练数据的输出端要针对这个词修改,比如只要输入端有China的正面描述,那么把相应的输出端手动修改为负面描述。
这两件事儿必须同时做,否则会造成不包含这个词句子的大量误译。
这两件事儿都违背了工业界效率至上的原则,因为都需要大量的人工修正。更何况,如果是要刻意抹黑一个国家,那么还需要在训练集里区分包含这个国名的句子是褒义还是贬义,褒义的就改掉,贬义的不改。这又增加了训练数据的噪声。
这种费力不讨好的事情,我认为Google是不会干的。
最后,即使我们没有这样的背景知识,仅从逻辑,也可以判断Google不太可能“夹带私货”。你想啊,假设Google在英译中的时候刻意抹黑中国,那它这样做给谁看呢?
谷歌服务中国大陆用不了,绝大部分中国人也上不了twitter,那谷歌费时费力的做一个没有“目标用户”的“功能”干什么呢?
吃饱了撑的?
相信这种阴谋论的人倒真可能是吃饱了撑的,但作为要对股东负责的上市公司,吃饱了撑的可能比较小。
好了,我相信明眼人已经看出来了,本文其实并不是在讨论Google翻译有什么问题,而是想借这个事情,探讨我们应该怎样去思考问题,从而少上一些当。
现在资讯发达,但不是每一条资讯都是有益的。我经常说,做自媒体的,归根结底只有两类:一类努力保持你的愚蠢,一类努力让你更加明智。而我,属于后者。
那些造谣的或则故意传递误导信息的人,自己本身是不相信谣言的,就像贩毒的自己不吸毒一样。他们之所以会这样做,是因为他们知道你会相信。这就够了,因为这是一门生意。
世上所有的生意,其成败都取决于人口结构。目前中国人口结构是这样的:绝大多数人不具备科学素养,也没有思辨能力。90%的人文化水平在高中以下,接近一半的人口在贫困线挣扎。
连总理都说实话了,我们更没有必要粉饰太平。
针对这种人口结构,做生意的人尤其是做自媒体的有两种选择:一是迎合这种人口结构,生产反智的内容。二是坚持产出高质量、科学的内容,以期一点一点的改变人口结构。
绝大部分人会选择第一条路,这就是为什么如果你最近读到谷歌翻译的文章,可能除了这一篇,全部都是告诉你谷歌夹带了私货。这其实是理性的选择,而且很容易成功,不信你看公众号的头部大号,基本上全部是造谣和生产反智文章的。以目前中国的人口结构,如果你不写假东西,很难有上千万粉丝。
在这一点上,我很不理性,甚至有点理想主义,总希望通过自己坚持不懈的传播科学常识,能够慢慢的让我国的人口结构向积极的方向变化。
有人收智商税,有人用高质量的内容换取应得的报酬,我选择做后者。
有人把爱国当作生意,有人把爱国当作责任,我选择做后者。
专题:事实核查进入专题 >>
秦刚“内部讲话“流出,称中美战争不可避免?(组图)

台当局拒绝大陆鸡蛋,网传“澳洲转销大陆鸡蛋”(图)

事实核查:普京真的在习近平面前下跪了吗?(图)









 +61
+61 +86
+86 +886
+886 +852
+852 +853
+853 +64
+64


